离散时间奖励有效地指导从系统数据中提取连续时间最优控制策略
该项研究由一个国际科学家团队领导,其中包括陈慈博士(广东工业大学自动化学院)、谢丽华博士(新加坡南洋理工大学电气与电子工程学院)和谢胜利博士(粤港澳智能离散制造联合实验室、广东省物联网信息技术重点实验室),并由刘逸璐博士(美国田纳西大学电气工程与计算机科学系)和 Frank L. Lewis 博士(美国德克萨斯大学阿灵顿分校 UTA 研究所)共同参与。
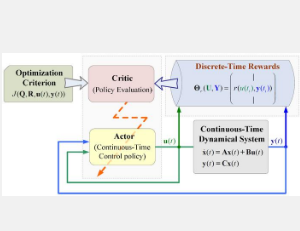
奖励的概念是强化学习的核心,也广泛应用于自然科学、工程学和社会科学。生物通过与环境互动并观察由此产生的奖励刺激来学习行为。奖励的表达在很大程度上代表了系统的感知,并定义了动态系统的行为状态。在强化学习中,寻找能够解释动态系统行为决策的奖励一直是一个开放的挑战。
该工作旨在提出在连续时间和动作空间中使用离散时间奖励的强化学习算法,其中连续空间对应于物理定律描述的系统的现象或行为。将状态导数反馈到学习过程中的方法导致了基于离散时间奖励的强化学习分析框架的发展,这与现有的积分强化学习框架有本质区别。“当想到将导数反馈到学习过程中的想法时,感觉就像闪电一样!你猜怎么着?它在数学上与基于离散时间奖励的策略学习有关!”陈回忆起他的顿悟时刻说道。
在离散时间奖励的指导下,行为决策律的搜索过程分为前馈信号学习和反馈增益学习两个阶段。研究发现,利用基于离散时间奖励的技术可以从动态系统的实时数据中搜索连续时间动态系统的最优决策律。上述方法已应用于电力系统状态调节,实现输出反馈的最优设计。该过程省去了动态模型辨识的中间阶段,并通过从现有的积分强化学习框架中去除奖励积分算子,显著提高了计算效率。
本研究利用离散时间奖励引导来发现连续时间动态系统的优化策略,构建理解和改进动态系统的计算工具,该成果可在自然科学、工程学和社会科学领域发挥重要作用。
该工作得到了国家自然科学基金和广东省基础与应用基础研究基金的资助。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。